大家好,我是郭立员~
这两天群友接了一单定制脚本的活,采集500彩票网的开奖数据,具体细节我没问,通过问我的问题,我猜猜采集的数据可能是这个:

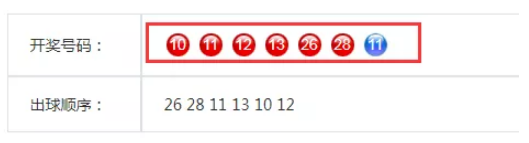
采集的目标网址:https://kaijiang.500.com/shtml/ssq/03001.shtml
遇到的问题是啥呢?
使用按键直接获取网页源码得到的结果是这样的:
- TracePrint url.get("https://kaijiang.500.com/shtml/ssq/03001.shtml")
- 当前脚本第1行:<html>
- <head><title>301 Moved Permanently</title></head>
- <body bgcolor="white">
- <center><h1>301 Moved Permanently</h1></center>
- <hr><center>nginx</center>
- </body>
- </html>
返回的结果是301重定向(并不是报错),无法获取到网页的html源码,我用浏览器自带的抓包调试工具看了一下,也没有跳转到别的网址,猜测是网页为了限制爬虫采集,做了一个假的跳转。
因为浏览器可以正常访问页面,所以想到的方法就是伪装成浏览器获取网页源码。
说是伪装,其实就是在http请求头里面加上User-Agent参数,很多做过抓包协议的人都懂的。
这个文章就这么一个知识点,直接上源码:
- Import "shanhai.lua"
- Dim uri = "https://kaijiang.500.com/shtml/ssq/03001.shtml"
- Dim hader = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) Apple WebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"
- Dim date1 = {"url":uri,"code":"gb2312", "cookie":"", "header":{"User-Agent":hader}}
- Dim login = Url.HttpPost(date1)
- TracePrint login
- Dim arr=shanhai.RegexFind(login,"<li class=""ball_.-"">(.-)</li>")
- For Each k In arr
- TracePrint k
- Next
- Dim haoma=shanhai.RegexFind(login,"出球顺序:.-<td>(.-)<")
- TracePrint haoma(0)
还有一点需要注意的,网站编码是GB2312,所以HttpPost命令的code需要修改一下,否则网页中汉字部分会出现乱码。





 闽公网安备 35010002000112号
闽公网安备 35010002000112号