xTask 2 是大概 5-6 年前我发布的一个按键精灵脚本开发框架,起初用于内部的一个项目,随着框架不断完善,我把他发布到了论坛上,当然,很快帖子就沉了。
后来我也没在这方面投入过多的精力,最近一直想写一些教程,尽可能的提升整个社区的水准,但这种教程不好写。
东西太深了,就得用很多话细细的讲,不然很容易让听众直接懵掉,东西太浅了又没什么用,按键也是个老论坛了,很多东西其实一直都有。
倒是架构方面的东西,很少有人讲,脚本工具嘛,很多时候讲究个简单粗暴,干就完了。
架构多数时间都是用在比较大的项目上的,为项目增加灵活性、可维护性,让模块增删变的更容易,这东西在脚本里算不上刚需。
但老实说,如果你代码写个几万行就开始头疼了,那多半是架构方面的能力不太足,这时候学更多的命令使用方法其实已经没办法进步了,更多的,是需要提升对数据的形态组织和掌控能力,也就是所谓的架构能力。
何谓架构?架构就是归纳。
有条理的人总是能把家里收拾的干干净净的,什么东西放在什么箱子里,这就是架构,你的东西明确清晰,就不容易出事,不然就很容易翻车,今天身份证找不到了,明天社保卡没了,后天钱包空了吃完饭留餐厅里给人家刷盘子抵债,这就是架构能力不行,数据、命令、逻辑、流程无法融汇贯通,少量代码和数据还好,一旦数据量上来了,脑瓜子嗡嗡的。
所以严格来说,这也属于内容的一部分,和数据结构、编译原理、算法导论属于同一个范畴,但与这几个兄弟不一样,架构其实更接近习惯,条理强的人整这个东西就是比莽的要更容易,当然,这些玩意的习惯也好养成,多的不说,给个忠告:不要试图在打地基的阶段偷工减料,你在一开始节省多少时间,未来就要十倍百倍的返还回去。
之前的教程也讲了一些怎么让自己的代码看起来更舒服的写法,今天换个角度讲架构,从解析我一份古老的工程开始,xTask上面也介绍过了,感兴趣的兄弟们可以看一下我的原贴:
http://bbs.anjian.com/showtopic-646958-1.aspx这是个开源项目,大家都可以改来自己用,有兄弟不会下载源代码,最简单的方法是安装个 git,然后cmd运行:
- git clone [url]https://gitee.com/xywhsoft/xTask2[/url]
就可以把代码下载到当前目录了,或者在gitee上注册个账号,然后点文件列表上面的【克隆/下载】按钮,弹出界面里有个下载 zip,点一下就能下载源代码了;原贴也有生成好的小精灵可以用。
源代码下载完,其实就是个按键精灵2014,直接运行【按键精灵2014.exe】就行了,里面只有一个脚本,就是我们项目的源代码了,打开就能看到。


xTask 是一个事件驱动的程序,和普通脚本点击开始运行不同,它是通过界面响应来跑的,我们可以从QUI开始看起,就几个界面,也蛮简单的:

主要的界面就这么多,接下来我们把抽象化的数据具象化,来告诉大家,为什么我们要这么设计界面。
首先开发 xTask 的原始需求是,我需要在一个脚本里,运行若干个脚本,然后我要能够配置这些脚本的运行计划,并且这些脚本要有不同的工作模式,还得有数据库来存储,然后这个脚本要支持分布式部署(说人话就是可以部署到很多台机器,并且随时能添加新的机器,也随时能删除掉一些机器)……
于是,我们的原始数据输入里,最最重要的几个东西就付出水面了吧?
一个是项目(就是一个一个的子脚本)、一个是计划任务(就是几点运行哪一个脚本)、再加一个运行时的任务(就是正在跑的脚本数据)
顶层数据就这么敲定了,其他东西都是顶层数据的附属,属于二等公民。
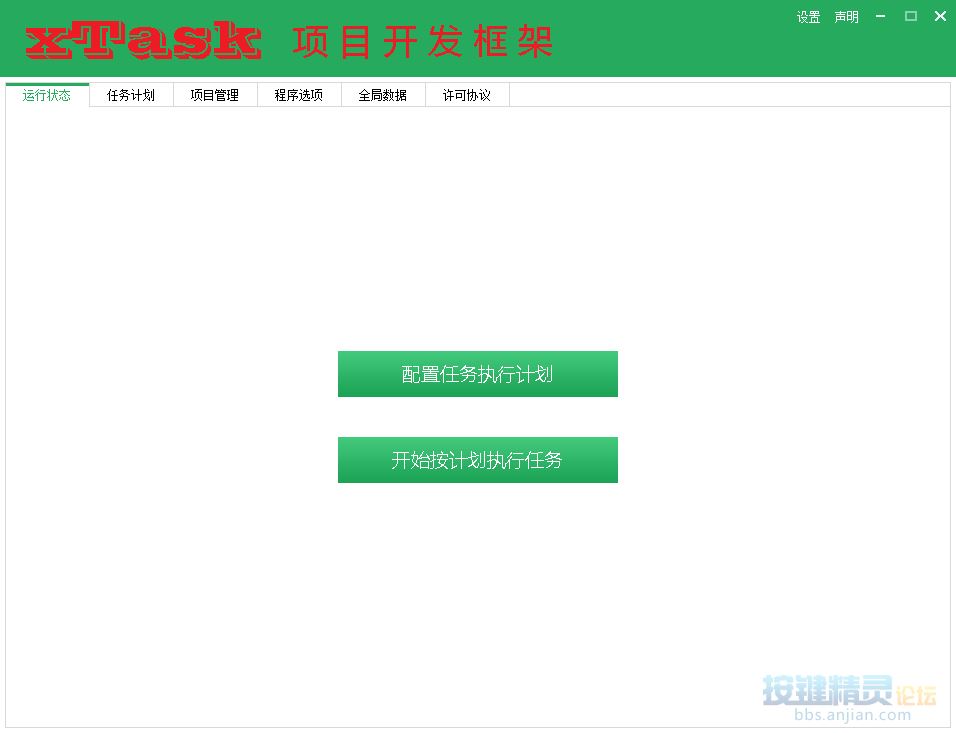
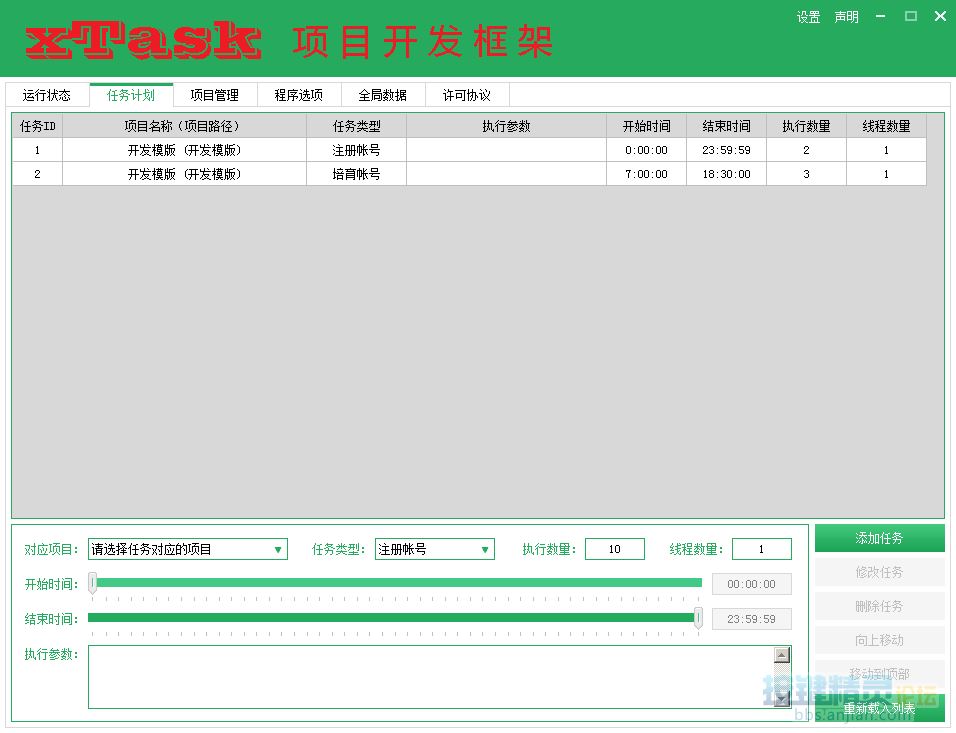
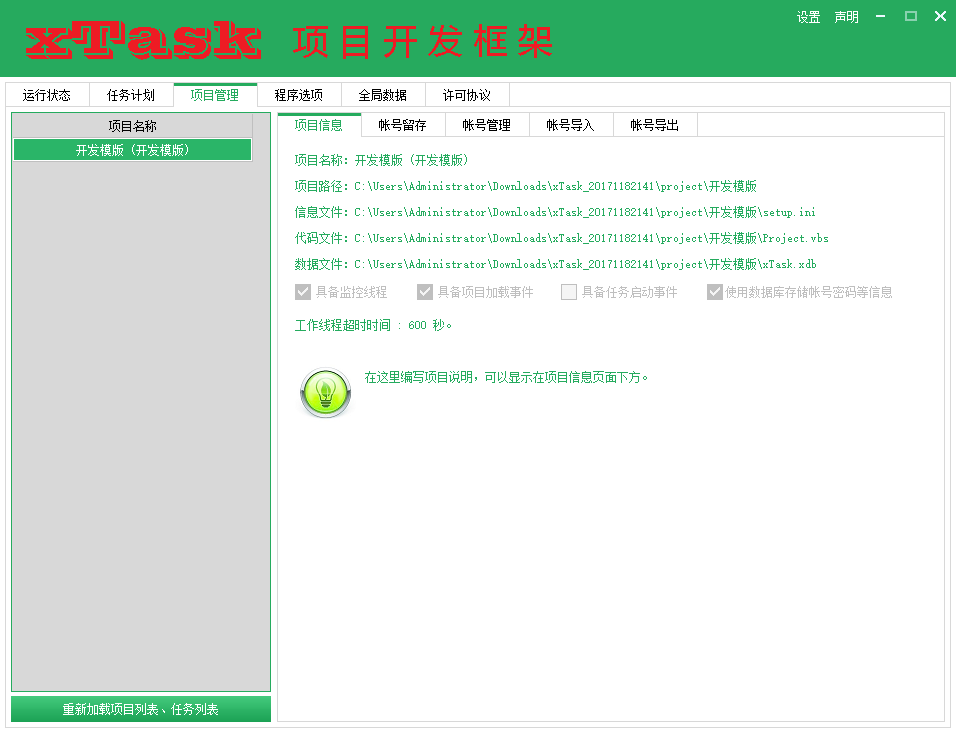
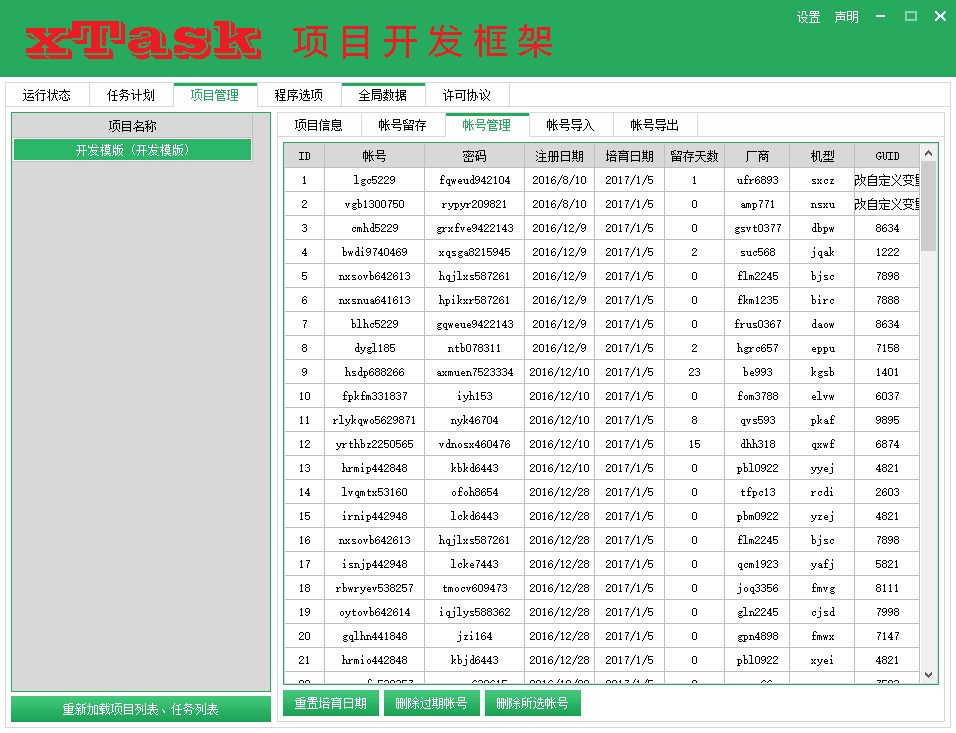
这三个数据,我们要让他具象化起来,于是就设计了【运行状态】、【任务计划】、【项目管理】三个界面。
然后呢,我这个人对于数据的掌控是有执念的,不管任何情况下,数据量有多少,所有数据我都希望能够展开来给我看,当然数据自己不可能展开啦,只好我用代码让他们展开来。
这一步的意义其实很大,能够节省未来我们大量的调试时间,于是,我们设计了【全局数据】这个界面。
全局数据界面下,有4个子界面,分别是:
Global:全局数据,相当于全局变量保存起来。
Project:子脚本的数据(对应项目管理)
Task:计划任务的数据(对应任务计划)
Thread:运行时的线程数据(对应运行状态)
再加上配置界面、开源协议界面,整个主界面就算完成了,你看,我们归纳好自己要管理的数据,再把他们可视化,一切并不复杂,一张界面就这么做出来了,很整齐。
然后我们来看数据的形态,除了基础数据类型以外,还有一些基础的结构化数据,比如:数组、表。
对于按键精灵X来说,对这些数据的支持与生俱来,但按键精灵2014就比较蛋疼了,为此我不得不自己动手,丰衣足食,为按键精灵2014加上了这方面的支持,详细的代码部分,我会在之后展开来讲。
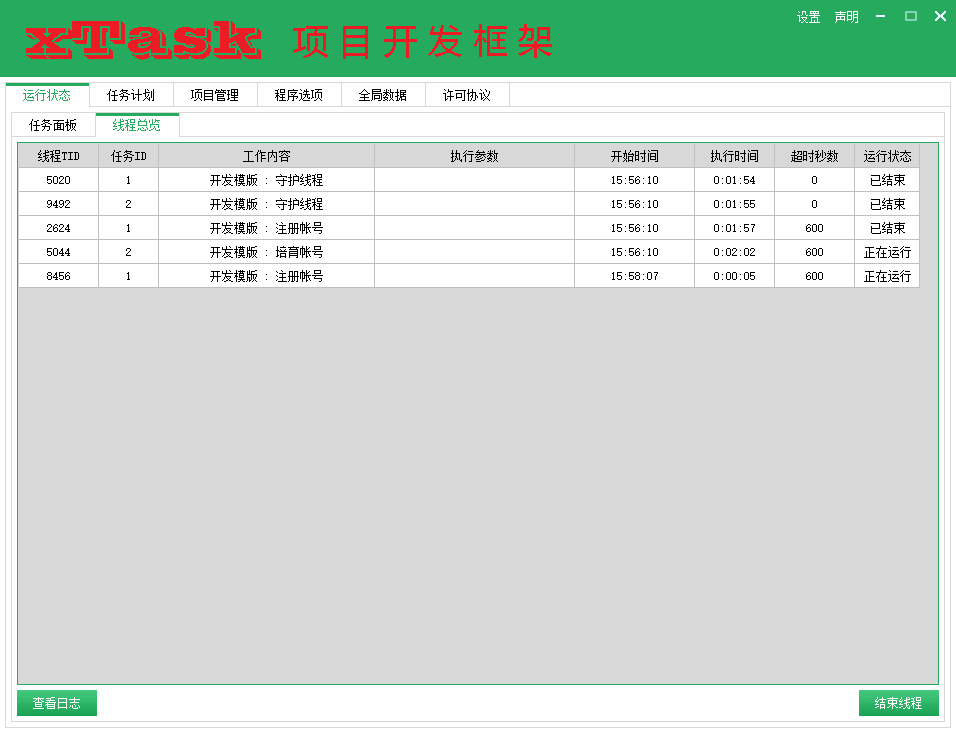
先来看界面,首先是【运行状态】:
当脚本跑起来之后,我们需要解除两类数据,第一个是计划任务对应的计划,一个是计划对应的线程,他们都应该是数组结构的,因为可以展示为列表,当然,也可以用比较复杂的树结构来描述它,不过按键精灵对树列表的支持不太行,所以当我产生这个想法不久后,就放弃了,转而用两个列表来实现,最终效果如下:
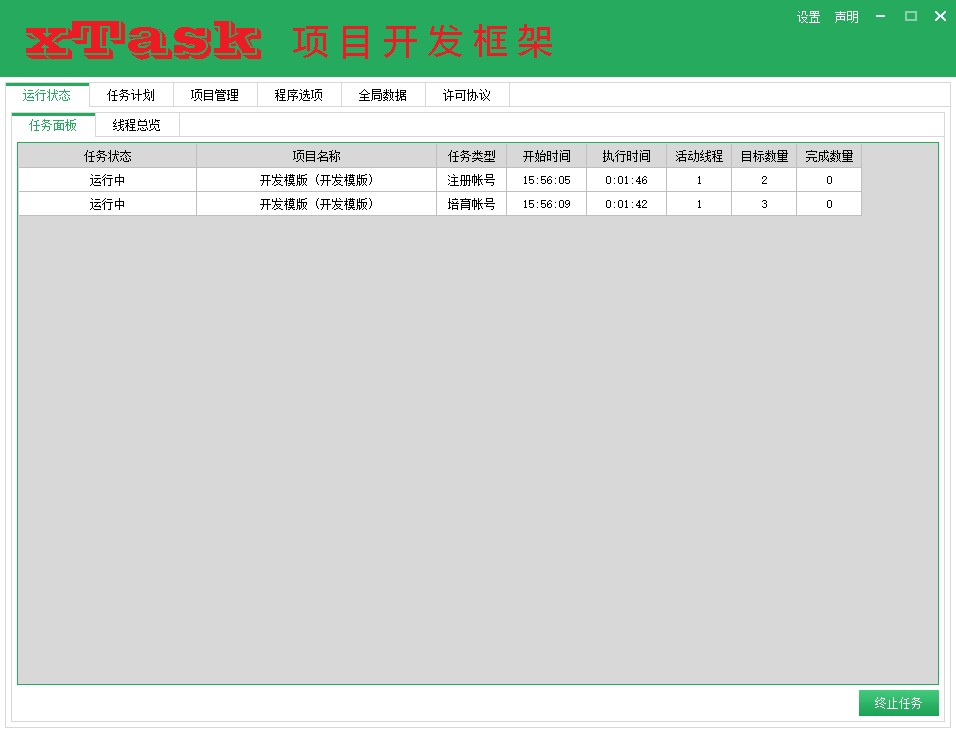
同样的思考方式,我们的任务计划界面也将是列表的:
我们的项目管理也是列表的,不过项目管理的选项要多很多,因为组成一个子项目所需要的数据,和一个独立的脚本其实差不多,再精心筛选之后,我留下了一些字段,也留下了一些定制化的能力:
界面的构建,到这里就结束了,现在回头整理一下我们的数据模型吧,这里是重点,需要仔细理解:
1. 以项目为核心因为我们的基本需求是可能要同时组织几十上百个子项目,每个子项目都实现一套类似的功能接口,因此项目管理是我们这个框架的绝对核心功能。
解决问题先解决数据模型,既然这些项目要实现的功能都差不多,我们可以很容易的把数据给提取出来,形成一个表,例如这样:

每一个项目都有这些数据,同时还带一个小的数据库,这个数据库存储与项目有关的所有数据,每个游戏账户是一条数据,这样,一个表 + 一个表格,我们的数据模型就搭建完了。
有了数据模型,设计出上面的界面,就不奇怪了吧? 这就是优雅的开发顺序,一切自然而然的发生,不需要过多思考,顺手为之就可以把事情做的很好了,也是做架构的魅力。
2. 以计划任务为时间线项目有了,我们要把项目跑起来,还得做个计划任务的界面,让项目能够在每天的什么时候固定来跑。
计划任务也是需要一些数据的,老规矩,我们先把数据的形态给整理好,然后用这些数据做出界面来,这里需要注意,计划任务的数据要分为两部分,一部分是【任务计划】设置页面由用户配置的静态数据,另一部分是计划任务跑起来之后,记录的动态数据,最终设计如下:

通过这些数据,我们把静态的摘出来,形成了【任务计划】界面,再把动态的部分摘出来,形成了【运行状态】的【任务面板】界面。
3. 脚本运行后,动态的将数据组织起来最后,真正承载我们脚本运行的东西,我们不能忽略了,是线程!
写多线程按键精灵工程,线程一定要管理好,不要求大家有严格的线程池管理能力,至少,每个线程的状态你得整明确了,每个线程的运行时数据也不能太糊涂,不然翻车了,崩溃了,连问题产生的原因都不知道,那不是就芭比Q了?
这部分我直接上设计了:

好了,这份数据设计,最终就形成了【运行状态】的线程总览界面。
接下来是架构师的自我修养第二步,我们要开始写代码了。





 闽公网安备 35010002000112号
闽公网安备 35010002000112号